Team Fancy: Wuwei Cai, Jizhou Yang, Yufei Xie, Menglin Wang
Introduction
As the significant advances in the field of face recognition, Deep Network, like FaceNet [1], performed almost perfectly in academics. However, we all have the experiences that your iPhone wouldn’t ‘know’ you for some reasons, especially for girls with makeup. Due to the noise of input pictures in application scenarios, Face Recognition technique requires not only modeling network, which have been well developed, but also picture pre-processing algorithms.
Compare to other noises that input images might have, makeup is a relatively frequent and formalized one. The applications of face recognition might benefit more from de-makeup technique. Therefore, our team is aiming to develop a network that can remove the makeup. What’s more, the de-makeup network itself is also a helpful and entertaining application.
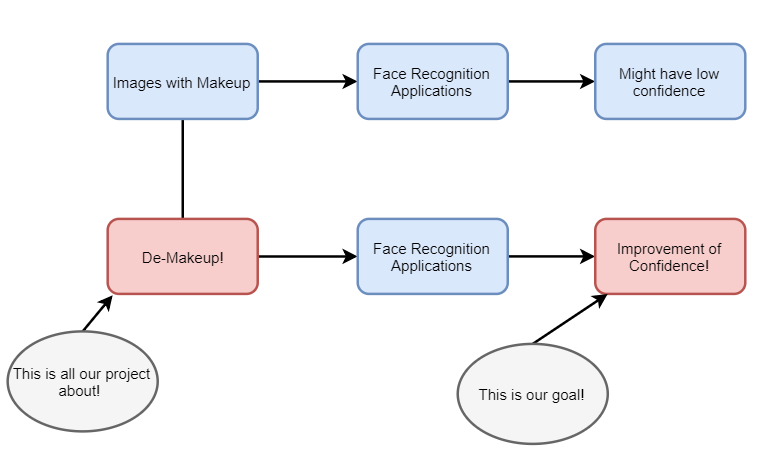
Figure. 1 Project Overview
Problem formulation
As the significant advances in the field of face recognition, Deep Network, like FaceNet [1], performed almost perfectly in academics. However, we all have the experiences that your iPhone wouldn’t ‘know’ you for some reasons, especially for girls with makeup. Due to the noise of input pictures in application scenarios, Face Recognition technique requires not only modeling network, which have been well developed, but also picture pre-processing algorithms.
Compare to other noises that input images might have, makeup is a relatively frequent and formalized one. The applications of face recognition might benefit more from de-makeup technique. Therefore, our team is aiming to develop a network that can remove the makeup. What’s more, the de-makeup network itself is also a helpful and entertaining application.
Due to the lack of aligned images (before and after makeup), this de-makeup problem is tackled with an unsupervised approach. We used cycle Generative Adversarial Network(cycle GAN), based on the framework of cycle-consistent generative adversarial networks, to produce de-makeup face images. The approach include two asymmetric networks: a forward network transfer makeup style, whereas a backward network removes the makeup.
The network is trying to learn mapping functions between two domains, X and Y. The two mapping included in our model is and
. Two adversarial discriminators
and
are also introduced, where
is aiming to distinguish between images X and transformed images F(y) and
is aiming to distinguish between images y and transformed images F(x). The lost functions involved in our model can be defined as below:
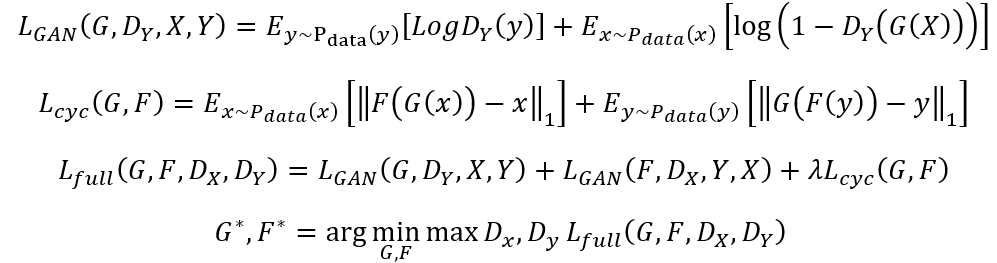
Equation. 1 Loss function of cycleGAN [2]
Approach
Our project can be roughly divided into three phase and within each pahse, we solved different problems.
- Data collection and literature research:
In the beginning of our project, we reviewed related paper and developed our method. In addition, we contacted the author of BeautyGAN [6] and were authorized to use their large Makeup Transfer dataset. To enrich our training in advance, we also collected images manually, but due to the poor training performance, these data were discarded.
- Implementation and training:
After the settlement of method and data, we finished the implementation of cycleGAN network using Tensorflow, referring to the Zhu's paper[2] and some high-stared github respository, and trained on Google Cloud Platform.
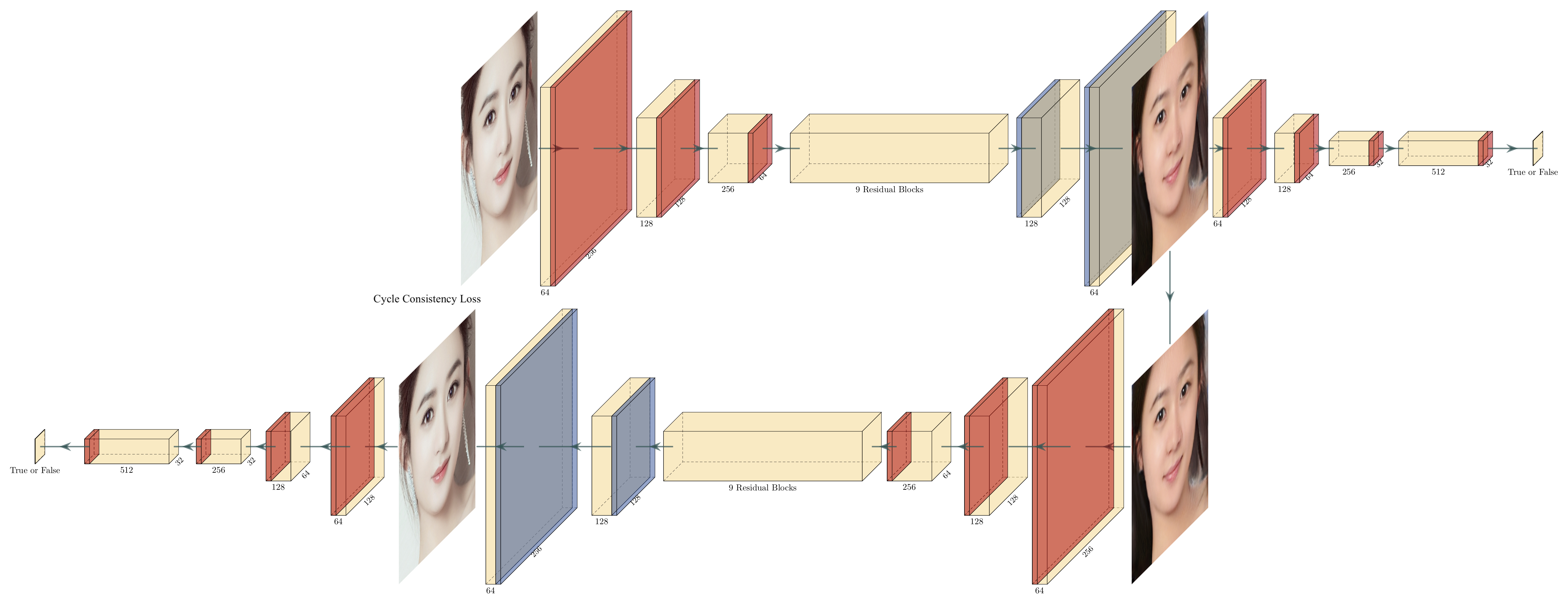
Figure. 2 Cycle GAN Structure
- Optimization of performance:
In this process, we were iterating the process that updateing our method depending on feedbacks of training result and in the end, we increased our output performance significantly. In the process, we applied three solution helping with our performance.
- After each iteration, we fine tuned the parameters to get better result.
- We categorized our training dataset depending on skin and hair colors, restrcting the no-makeup domain andlimiting the features will be learned.
- Given the makeup of eye region is different from lip region and skin region, a face parsing algorithm that segment face into component might be applied before training. However, in the origin paper [3], the author didn't describe the parsing algorithm in detail. We tried to develop our own parsing algorithm, but due to the limited time we have, we didn't finish the segmentation.
Comparision to the past works
We found several literatures that dealing with the similar problem, makeup transfer and removal, for instance PairedCycleGAN [3], makeup detector and remover framework[4], and Image-to-Image Translation [2]. In the above literature, their work can produce impressive de-makeup face image, however, to our best knowledge, relative less investigator tried to make use of the de-makeup networks on top of face recognition application.
Results

Figure. 1 Test Input images (First Row), primary result (Second Row) and final result (Third Row)
As shown above, we can see that in our primary output, instead of transfering makeup, the network was actually transfering ‘race’ and in the meantime, keep the images aligned. Even thought this was an interesting application, it did reflected our one of our problem. The distribution of our training data is biased by the selection of images, which will make the mapping functions learned by our network odd and produce funny results. When we go back to our dataset, we found our data was biased in several ways and we improved the performance after data catorization and tuning.
- Skin and hair color: Due to people from different race may have different skin and hair color, this will affect our model in many ways. For instance, the model might learn gold hair feature and applied it to a black hair girl, which will make it looks like our primary output. We categorized our training data by skin and hair color and as shown above, the performance was imporved.
-
Background: Background in the images always severe as noise and our network might transfer the backgound into abnormal color or mix it with hair. But we haven't developed an effective way to solve this problem.



Figure. Test input image (left), and results with abnormal background (primary (middle) and final (right))
-
Other noise in image: Other noise might come from accessaries, glasses, hat or other object in the image.These images are only minor part of training dataset, but they will affect the performance a lot. After cleaned our training dataset, we can see the result is robust to these noise.






Figure. Test Input images with other noise (left), primary result (middle) and final result (right)
In addition, we use Microsoft Azure Face recognition system to test whether our final result can better match the input. We put the images with make-up into the recognition library and check the similarity between our generated images without make-up and the images of the recognition library.
The following figure shows the confidence distribution of the primary result and final result.
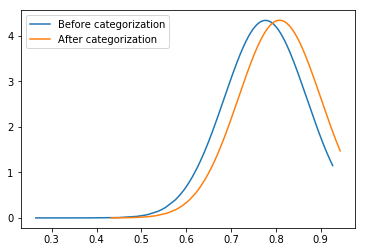
It can be seen from the following figure that the average confidence increases 4 percent and P-value is less than 0.001. This indicates that the distributions of two groups of result are different. In otherwords, the final result is better than the primary result.
| Data | Mean | SD | Min | Max | T | P value |
|---|---|---|---|---|---|---|
| Primary | 77% | 9% | 26% | 92% | ||
| Final | 81% | 9% | 43% | 94% | -7.91 | <0.001 |
Future work
Given our results, we also found some further problems and corresponding solutions, but due to time or other limitation, these solutions haven’t been implemented yet.
- Our network currently can deal with asian images, since, after cleaning, our dataset contains only asians. In the future, if we can have enought data for the network to learn necessary features, we might use a network for classification, for instance skin color or hair color, and use the corresponding network trained with specific data.
- There were part of our result contain images affected by the background. In our project, the background always serves as noise and affect our generative performance. Therefore, we planed to use parsing algorithm to label our image which can reduce the effect of background noise. In addition, we noticed that the eye, lip and nose areas of face images have significant different styles and we can also use parsing algorithm to segment these areas which will be trained separatelly.
References
[1] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. arXiv preprint arXiv:1503.03832, 2015.
[2] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. CoRR, abs/1703.10593, 2017.
[3] Chang, H., Lu, J., Yu, F., Finkelstein, A. Pairedcyclegan: Asymmetric style transfer for applying and removing makeup, in: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[4] S. Wang and Y. Fu. Face behind makeup. AAAI Conference on Artificial Intelligence, 2016
[5] C. Chen, A. Dantcheva, and A. Ross. Automatic facial makeup detection with application in face recognition. In ICB, pages 1–8, 2013
[6] Li, T., Qian, R., Dong, C., Liu, S., Yan, Q., Zhu, W., Lin, L.: Beautygan: Instance-level facial makeup transfer with deep generative adversarial network. In: ACM MM (2018)